jmanteau
Mon coin de toile - A piece of Web
Matching IPs to Subnets in Python in an Efficient Way
Introduction
If you work in networking, you’ve likely matched IP addresses to subnets. This helps figure out which server, workstation, or cloud instance belongs to a particular network or site.
Many network engineers use simple methods for scripting this. Often, making the IP lookup process better can speed up a slow script significantly.
In this post, we are going to see the most common libs in python to do IP lookup as well as compare their performance.
TL;DR: Use pytricia lib for IPs to subnets lookup.
Longest Prefix Match (LPM)
The Longest Prefix Match (LPM) algorithm helps route (forward) data in IP networks. It picks the best match for the destination address from the routing table (more precisely from the Forwarding Information Base or FIB).
An IP address has two main parts: the network (or subnet) part, and the host-specific part. For example, in “192.168.0.0/24”, “192.168.0.0” is the network address, and “24” is the prefix length, showing how many bits are for the network part. The rest are for host addresses. IPv4 addresses are 32 bits long. So, a “192.168.0.0/24” subnet uses 24 bits for the network, leaving 8 for host addresses, allowing for 256 hosts. IPv6 is similar but uses 128 bits.
The router uses an IP routing table, or FIB, to decide how to forward packets. This table lists network address entries, or prefixes, of potential destinations. To find the best match for an IP address, the router looks at all entries that could include the address. For example, for “192.24.14.1”, entries like “192.24.0.0/18” and “192.24.12.0/22” could work. The router chooses the entry with the longest prefix, meaning the most specific match. So, “192.24.12.0/22” would be chosen over ““192.24.0.0/18” for better specificity. Hence, the IP packet forwarding algorithm is called longest prefix match (LPM).
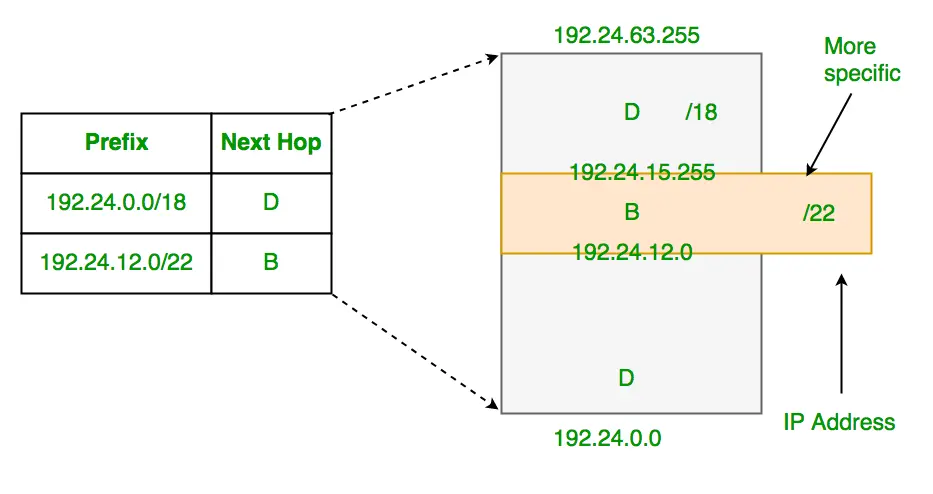
Longest Prefix Matching in Routers
Most routing tables, like those in the Linux kernel or software routers, use a Patricia Trie structure. Researchers have studied other structures to speed up LPM. The aim is to route packets as quickly as possible. In hardware, such as packet-switching ASICs, LPM often uses TCAM (Ternary Content-Addressable Memory). Python, like many programming languages, provides libraries and tools that can be used to implement the Longest Prefix Match (LPM) algorithm. Those libaries provides different strategies that we are going to compare.
Understanding Tries and Radix Trees
We just mentionned Radix Tree also known as Patricia tree. What are they exactly ?
What is a Trie?
A trie is a tree-like data structure that organizes strings character by character. Each node in a trie represents a character. These nodes connect to form words or prefixes. The root node stands for an empty character, and paths from it represent different strings.
Imagine a trie holding the words “cat”, “car”, “cart”, “cater”, “carte”, “catnip” and “catnap”. Starting from the root, you trace paths through nodes for each character to find a word. This way, retrieving a string involves moving from the root to a node that marks the end of the string.
Tries excel in prefix searches, making them ideal for dictionaries, autocomplete features, and other applications needing fast prefix-based searches.
Radix Trees Explained
Radix trees, also known as Patricia trees, are an evolution of tries. They compress consecutive nodes into a single node if there’s only one child. This method stores character sequences instead of single characters at each node, reducing the number of nodes and edges. Let’s reuse the words “cat”, “car”, “cart”, “cater”, “carte”, “catnip” and “catnap”.
This compression makes radix trees more space-efficient without losing the quick retrieval feature of tries. Each node might represent a full string or a prefix, keeping the connectivity based on shared prefixes.
Key Benefits
- Tries provide fast search capabilities, particularly for prefix-based searches. They’re great for applications requiring quick access to words or prefixes.
- Radix Trees enhance tries by minimizing space usage. They’re suitable for handling large sets of data more efficiently.
Python IP addressing libraries

IPAddress
The ipaddress library comes built into Python. It’s designed to create, manipulate, and operate on IPv4 and IPv6 addresses and networks. This library is perfect for basic IP address manipulation and checks. Here’s how to use it:
- To handle IP addresses and networks, first import the library:
import ipaddress
-
Create an IPv4 address:
ip = ipaddress.ip_address('192.168.1.1') -
To work with an IPv4 network:
network = ipaddress.ip_network('192.168.1.0/24') -
Checking if an IP belongs to a subnet :
ip in network -> Boolean
NetAddr
netaddr is a powerful, external Python library for network address manipulation. It supports more features than ipaddress (allowing for the enumeration of all IP addresses in a subnet, handling of IPv6, and manipulation of MAC addresses, etc). Install it using pip: pip install netaddr
To use netaddr:
- To handle IP addresses and networks, first import the library:
import netaddr
-
Create an IPv4 address:
ip = netaddr.IPAddress('192.168.1.1') -
To work with an IPv4 network:
network = netaddr.IPNetwork('192.168.1.0/24') -
Checking if an IP belongs to a subnet :
ip in network -> Boolean
Py-Radix
py-radix is specifically designed for radix tree operations, enabling efficient storage and lookup of IPv4 and IPv6 addresses. It’s especially useful for applications that need to match IP addresses against large numbers of subnets quickly. Install py-radix via pip: pip install py-radix
Basic usage involves:
- Creating a radix tree and inserting IP subnets:
import radix
rtree = radix.Radix()
rnode = rtree.add("192.168.1.0/24")
- Checking if an IP belongs to a subnet :
rnode = rtree.search_best(ip) -> RadixNode
PyTricia
PyTricia offers a way to efficiently store and search for IPv4 and IPv6 addresses. Similar to py-radix, it uses a Patricia trie for fast lookups. Install PyTricia using pip: pip install pytricia
To use PyTricia:
- Initialize a PyTricia object and insert an IP subnet:
import pytricia
pyt = pytricia.PyTricia()
pyt.insert('192.168.1.0/24', 'Some value')
Checking if an IP belongs to a subnet : most_specific_subnet = pyt[ip] -> str
PySubnetTree
The PySubnetTree package provides a Python data structure SubnetTree which maps subnets given in CIDR notation (incl. corresponding IPv6 versions) to Python objects. Lookups are performed by longest-prefix matching. It’s built on top of a C++ library, providing fast lookups.
To use PySubnetTree:
- A
SubnetTreeobject is created and each subnet is added to theSubnetTree.
import SubnetTree
subnet_tree = SubnetTree.SubnetTree()
for subnet in subnets:
subnet_tree[subnet] = subnet
- Checking if an IP belongs to a subnet: find a matching subnet by querying the
SubnetTree. If the IP matches a subnet, the associated data (the subnet) is returned. If there’s no match, aKeyErroris caught.
results = {}
for ip in ips:
try:
matching_subnet = subnet_tree[ip]
results[ip] = matching_subnet
except KeyError:
results[ip] = None
Comparing them
We are going to create a python script to do this analysis with the following high level structure:
Data Generation:
- Generates a large number of random subnets and IP addresses within a specific range 10.0.0.0/8
- Saves generated subnets and IP addresses to pickle files for persistence, or loads them if they already exist.
Matching Functions: Implements several functions to match IP addresses to the most specific subnet they belong to. Each function represents a different approach or library usage.
Evaluation and Visualization:
- Measures the execution time of each matching function through repeated trials to assess their performance with
timeitlibrary. - Compares the matching results of all methods to identify discrepancies or confirm consistency across different approaches.
- Plots the execution times of each method using
matplotlibfor visual comparison.
Results
Let’s show the outcome for 1 000 IPs matched in 100 000 subnets :
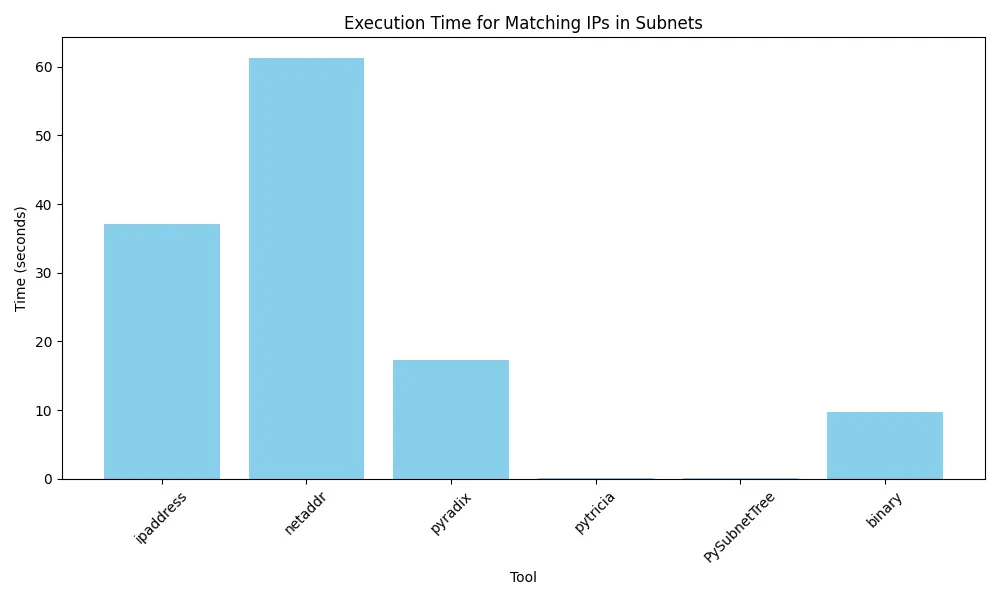
| Library | Execution Time (s) | Speed Difference (%) |
|---|---|---|
| pytricia | 0.10 | / |
| PySubnetTree | 0.15 | 59 |
| binary | 9.7 | 9 646 |
| pyradix | 17.3 | 17 145 |
| ipaddress | 37.1 | 36 921 |
| netaddr | 61.2 | 60 920 |
The result is quite clear with libraries using Patricia Trees are more advantaged than the classical ipaddress or netaddr (with binary still better than Py-Radix at this stage !).
I was quite surprised of the low-performance of pyradix compared to pytricia or PySubnetTree. But the two latest one are actively maintained whereas the latest commit in py-radix is in 2015.
The impact of performance is even clearer if we use 10 000 IPs matched in 1 000 000 subnets and pytricia absolutely shines here :
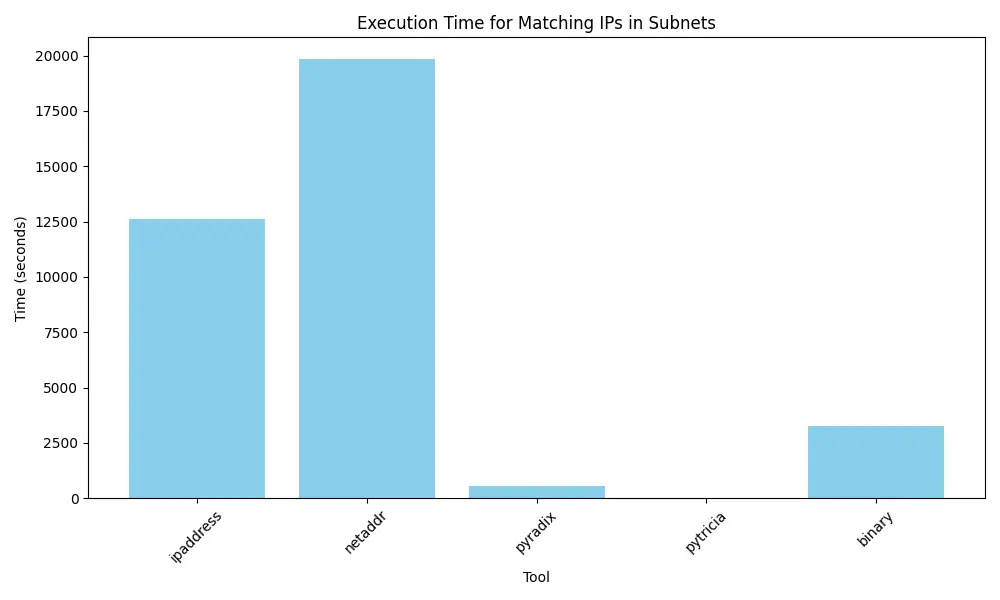
One thing for sure, I am going to actively use pytricia now if I have to do IP lookups in subnets.
Code
import ipaddress
import os
import pickle
import random
from itertools import combinations
# Path settings
subnets_file = "subnets.pickle"
ips_file = "ips.pickle"
NB_SUBNET = 100000
NB_IPS = 1000
TESTING_ITERATIONS = 3
GENERATE_ALWAYS = True
def generate_subnets():
subnets = []
for _ in range(NB_SUBNET):
prefix_length = random.randint(
10, 30
) # Choose a random prefix length between /10 and /30
subnet = ipaddress.IPv4Interface(
f"10.{random.randint(0, 255)}.{random.randint(0, 255)}.{random.randint(0, 255)}/{prefix_length}",
).network
subnets.append(str(subnet))
return subnets
def generate_ips():
ips = [
f"10.{random.randint(0, 255)}.{random.randint(0, 255)}.{random.randint(0, 255)}"
for _ in range(NB_IPS)
]
return ips
def save_to_pickle(data, file_name):
with open(file_name, "wb") as f:
pickle.dump(data, f)
def load_from_pickle(file_name):
with open(file_name, "rb") as f:
return pickle.load(f)
# Check for existing datasets and generate if not present
if not os.path.exists(subnets_file) or GENERATE_ALWAYS:
print("Subnets dataset not found. Generating...")
subnets = generate_subnets()
save_to_pickle(subnets, subnets_file)
print("Subnets dataset generated.")
else:
subnets = load_from_pickle(subnets_file)
print("Subnets dataset loaded.")
if not os.path.exists(ips_file) or GENERATE_ALWAYS:
print("IPs dataset not found. Generating...")
ips = generate_ips()
save_to_pickle(ips, ips_file)
print("IPs dataset generated.")
else:
ips = load_from_pickle(ips_file)
print("IPs dataset loaded.")
def match_ips_in_subnets_ipaddress(subnets, ips):
import ipaddress
networks = [ipaddress.ip_network(subnet) for subnet in subnets]
results = {}
for ip in ips:
ip_obj = ipaddress.ip_address(ip)
# Filtering and then directly sorting network objects based on prefixlen
matching_subnets = sorted(
[net for net in networks if ip_obj in net],
key=lambda x: x.prefixlen,
reverse=True,
)
if matching_subnets:
# The most specific subnet is the one with the largest prefixlength (reverse sorted)
results[ip] = str(matching_subnets[0])
else:
results[ip] = None
return results
def match_ips_in_subnets_netaddr(subnets, ips):
from netaddr import IPAddress, IPNetwork
networks = [IPNetwork(subnet) for subnet in subnets]
results = {}
for ip in ips:
ip_obj = IPAddress(ip)
matching_subnets = sorted(
[net for net in networks if ip_obj in net],
key=lambda x: x.prefixlen,
reverse=True,
)
if matching_subnets:
# The most specific subnet is the one with the largest prefixlen (reverse sorted)
results[ip] = str(matching_subnets[0])
else:
results[ip] = None
return results
# def match_ips_in_subnets_netaddripset(subnets, ips):
# from netaddr import IPNetwork, IPSet
# # Convert the list of subnet strings to an IPSet of networks
# subnet_set = IPSet([IPNetwork(subnet) for subnet in subnets])
# # Convert the list of ip strings to an IPSet of individual addresses
# ip_set = IPSet(ips)
# # Find the intersection of IPs and subnets to determine which IPs match which subnets
# matching_ips = ip_set & subnet_set
# # `matching_ips` now contains all IPs that fall within the specified subnets
# # We can now reverse-map these IPs to their respective subnets if needed
# # Prepare a dictionary to hold the result
# ip_to_subnet_mapping = {}
# # For each matching IP, find which subnet it belongs to
# for ip in matching_ips:
# for subnet in subnet_set.iter_cidrs():
# if ip in subnet:
# # Convert IP and subnet to strings for easier reading
# ip_to_subnet_mapping[str(ip)] = str(subnet)
# break # Stop looking once the correct subnet is found
# return ip_to_subnet_mapping
# # WILL NOT WORK AS IT WILL FIND THE LARGET MATCHING SUBNET AND NOT THE BEST ONE
def match_ips_in_subnets_pyradix(subnets, ips):
import radix
radix_tree = radix.Radix()
for subnet in subnets:
rnode = radix_tree.add(subnet)
rnode.data["subnet"] = subnet
results = {}
for ip in ips:
rnode = radix_tree.search_best(ip)
if rnode:
results[ip] = rnode.data["subnet"]
else:
results[ip] = None
return results
def match_ips_in_subnets_pytricia(subnets, ips):
import pytricia
pyt = pytricia.PyTricia()
for subnet in subnets:
pyt[subnet] = subnet
results = {}
for ip in ips:
try:
most_specific_subnet = pyt[ip]
results[ip] = most_specific_subnet
except KeyError:
results[ip] = None
return results
def match_ips_in_subnets_PySubnetTree(subnets, ips):
import SubnetTree
subnet_tree = SubnetTree.SubnetTree()
# Fill the SubnetTree with subnets. You can associate data with each subnet if needed.
for subnet in subnets:
subnet_tree[subnet] = subnet
results = {}
for ip in ips:
try:
# The lookup will succeed if the IP is in any of the subnets added to the tree.
# It returns the data associated with the subnet, which in this case is the subnet itself.
matching_subnet = subnet_tree[ip]
results[ip] = matching_subnet
except KeyError:
# If the IP does not match any subnet, catch the exception and set the result to None.
results[ip] = None
return results
def ip_to_binary(ip):
return "".join([bin(int(x) + 256)[3:] for x in ip.split(".")])
def ip_to_int(ip):
"""Convert an IP string to an integer."""
return sum(int(byte) << 8 * i for i, byte in enumerate(reversed(ip.split("."))))
def match_ips_in_subnets_binary(subnets, ips):
"""Match IPs to the most specific subnet."""
results = {}
subnet_info = []
for subnet in subnets:
subnet_addr, prefix_len = subnet.split("/")
subnet_int = ip_to_int(subnet_addr)
mask = (-1 << (32 - int(prefix_len))) & 0xFFFFFFFF
subnet_info.append((subnet_int & mask, mask, subnet))
for ip in ips:
ip_int = ip_to_int(ip)
best_match = None
for subnet_int, mask, subnet in subnet_info:
if ip_int & mask == subnet_int:
if best_match is None or best_match[1] < mask:
best_match = (subnet, mask)
results[ip] = best_match[0] if best_match else None
return results
import timeit
import matplotlib.pyplot as plt
def dynamic_timing_and_plotting(subnets, ips):
execution_times = {}
for name, func in globals().items():
if callable(func) and name.startswith("match_ips_in_subnets_"):
tool_name = name.split("match_ips_in_subnets_")[-1]
time_taken = timeit.timeit(
lambda: func(subnets, ips), number=TESTING_ITERATIONS
)
execution_times[tool_name] = time_taken
from pprint import pprint
pprint(execution_times)
# Plotting the execution times
plt.figure(figsize=(10, 6))
plt.bar(execution_times.keys(), execution_times.values(), color="skyblue")
plt.xlabel("Tool")
plt.ylabel("Time (seconds)")
plt.title("Execution Time for Matching IPs in Subnets")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
def testing_tools():
results = {}
for name, func in globals().items():
if callable(func) and name.startswith("match_ips_in_subnets_"):
tool_name = name.split("match_ips_in_subnets_")[-1]
results[tool_name] = func(subnets, ips)
discrepancies = []
matches = []
# Compare all pairs of results for discrepancies
for (tool1, result1), (tool2, result2) in combinations(results.items(), 2):
if result1 != result2:
discrepancies.append((tool1, tool2))
else:
matches.append((tool1, tool2))
# Printing the outcome summary
if not discrepancies:
print("All tools have produced identical results.")
else:
print("Discrepancies found between the following tools:")
for tool1, tool2 in discrepancies:
print(f"- {tool1} vs {tool2}")
# Also summarize tools that had matching results for completeness
if matches:
print("\nTools with matching results:")
for tool1, tool2 in matches:
print(f"- {tool1} and {tool2} have identical results")
testing_tools()
dynamic_timing_and_plotting(subnets, ips)